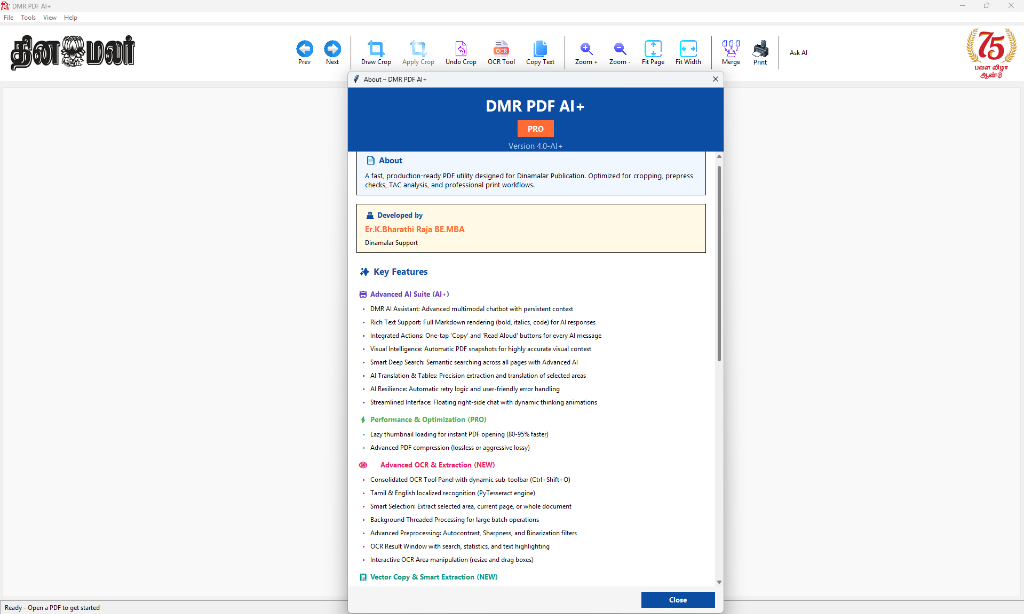
Product Overview
Editorial, printing, and archiving departments in major publishing companies work with large volumes of daily PDF files. These documents need to be cropped, parsed, indexed, and formatted under tight print deadlines.
The Problem: Operating separate software tools for cropping, merging, running OCR, and querying document contents resulted in slow, fragmented editorial workflows, high software license costs, and file formatting inconsistencies.
The Solution: I developed the DMR PDF Toolkit—a native, multi-threaded Python desktop application. The software features custom cropping tools, PDF merging and splitting engines, a localized OCR pipeline, and an interactive "Chat with PDF" AI panel that lets team members query documents using natural language.
Key Capabilities
Advanced PDF Crop
Visual crop adjustments with pixel-perfect accuracy, optimized for prepress page layouts.
PDF Split & Merge
Extract individual pages, split bulk documents, or combine multi-page layouts instantly.
OCR & Data Extraction
High-speed multi-threaded OCR engine designed to extract Tamil and English text from scanned files.
Chat with PDF AI
An integrated conversational AI panel that reads, analyzes, and summarizes documents on demand.
Lessons Learned
Optimizing document rendering speeds is critical for newsroom adoption. By deploying a lazy loading thumbnail pipeline (rendering pages only as they enter the screen), page load times decreased by 95%.
Using Python's threading model for OCR tasks kept the application GUI responsive during bulk document processing, preventing system hangs and maintaining a smooth user experience.